
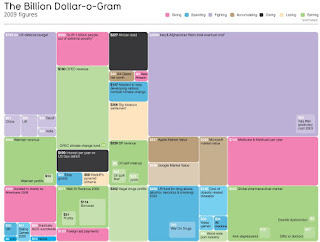
Stef van Grieken liet The Billion Dollar-o-Gram van David McCandless zien tijdens zijn presentatie als voorbeeld van wat je met Big Data kunt doen.”Als we Google aan Afrika geven hebben ze daar geen schulden meer”
Klik op afbeelding voor groter plaatje, of op de link voor de bron.
Op 20 november 2012 organiseerde de MWG een bijeenkomst over ‘Big Data in media’ in het Cool Brands House in Amsterdam. Sprekers waren online ondernemer Marjolijn Kamphuis, data cruncher en zelfverklaard nerd Stef van Grieken, online algoritme ontwerper Stephan Noller, media onderzoeker met oog voor nieuwe ontwikkelingen Nick North en mediabureauman van alle datamarkten thuis, Mervyn Brookson. Zelf mocht ik als ‘moderator’ van deze bijeenkomst optreden.
In deze blog een mix van mijn openingsspeech en een verslag van de bijdragen van de sprekers. Het MWG verslag (met foto’s) vindt u hier.
Big Data is big business, in elk geval voor de organisatoren van congressen. Als u na het lezen van dit stukje de smaak te pakken krijgt kunt u de rest van het jaar en volgend jaar ook elke week wel ergens een Big Data bijeenkomst bijwonen. Wat is Big Data? Daarover verschillen gelukkig de meningen. Anders waren al die middagen en congressen natuurlijk ook niet nodig. Er zijn deskundigen die het heel pragmatisch benaderen. Als u ooit heeft meegemaakt dat uw PowerPoint presentatie niet per e-mail verstuurd kon worden omdat ie te groot was, heeft u volgens hen al ervaring met Big Data.
Mijn eigen eerste ervaring met Big Data stamt uit 1985. Destijds mocht ik voor het Cebuco op een VAX computer het Tijdbestedingsonderzoek (TBO) uit datzelfde jaar analyseren. Ik heb het even nagekeken: Er waren 3263 respondenten, 672 kwartieren in de week, de ondervraagden konden per kwartier kiezen uit 270 bezigheden die ze of thuis konden doen, of buiten de deur. Als nevenactiviteit kon men kijken naar Nederland 1 en 2, of een andere zender, luisteren naar Hilversum 1 en 3, Hilversum 2, of een andere zender. Kortom, de wereld was nog overzichtelijk. De VAX computer deed ongeveer 8 uur over één SPSS uitdraai op het TBO. Het enige jammere was dat dezelfde computer ook gebruikt werd voor de ordering van de advertenties in de Nederlandse dagbladen. Nadat er 2 weken geen advertenties in de Nederlandse kranten geplaatst konden worden kreeg ik mijn eigen VAX computer. Nu analyseer je het Tijdbestedingsonderzoek op je laptop en vraagt een uitdraai een paar seconden.
James Gleick geeft in zijn boek The Information een overzicht van de groei van informatie in de wereld. In 1970 introduceerde IBM 2 mainframes, de modellen 155 en 160 met respectievelijk 768.000 bytes en 1 megabyte aan geheugen. Er was een aparte kamer nodig om ze op te stellen en je betaalde er ruim $4,6 miljoen voor. Bedenk dat u er vandaag niet eens één foto van uw mobiele telefoon op kwijt zou kunnen. In 1982, 12 jaar later kon je bij Prime Computer al een megabyte geheugen kopen op een printplaat voor $36.000. Vorige maand kocht ik een back-up schijf van een terabyte, 2 iPhones groot voor €119,95. Een terabyte is ruim een miljoen megabytes, 916 miljoen pagina’s tekst, 4,5 miljoen boeken, 350.000 foto’s van 3 mB, of 1600 CD’s van 650mB.
Seth Lloyd, quantum wetenschapper bij het MIT, heeft uitgerekend hoeveel informatie het universum nu bevat gerekend vanaf de Big Bang. Hij komt uit op 1090 bits (Gleick, 2011).
Waarom organiseert de MWG een middag over Big Data in media? Omdat Big Data de mediawereld drastisch gaat veranderen. De digitalisering zorgt enorme hoeveelheden nieuwe data over het (media) gedrag van de consument. Marjolijn Kamphuis liet zien hoe consumenten niet alleen via Facebook, Hyves en Twitter grote hoeveelheden persoonlijke data genereren maar ook via zelfregistratiesites/applicaties als het door haar opgerichte Foodzy.com. Als je wilt kun je elke hap die je neemt en elke stap die je zet, alsmede de gevolgen die dat heeft voor je gewicht en je bloeddruk vastleggen. Kortom, iemand die surft, zoekt, zijn of haar leven met anderen deelt op Social Media of probeert zijn eigen gedrag te monitoren genereert Big Data.
Als hij of zij televisie kijkt via de digitale Set Top Box: Big Data; als er een krant of tijdschrift wordt gelezen op een tablet: Big Data. Nick North van de mediatak van onderzoeksbureau GfK liet zien hoe die nieuwe datastromen gecombineerd kunnen worden met de bestaande bereiksonderzoeken om zo bijvoorbeeld meer robuuste gegevens over kleinere spelers op de mediamarkt te krijgen. Niet geheel verwonderlijk zag hij nog niet gebeuren dat daarmee die traditionele onderzoeksdata op den duur overbodig zouden worden.
De mediadata kunnen worden gekoppeld aan talloze andere databronnen. Eerder deze maand was ik op een bijeenkomst van de NPSO. Daar leerde ik dat de gemiddelde smartphone tegenwoordig 7 verschillende sensoren bevat. Als je die allemaal uitleest weet je onder meer waar iemand is, hoe snel hij of zij zich voortbeweegt of ie dat in horizontale of in verticale toestand doet, en zo voort. Big Data. Uw telefoon maakt op termijn het Tijdbestedingsonderzoek overbodig. Retailers komen om in de data. Kassa-aanslagen, uw bonuskaart, de Appie app, het is niet anders dan Big Data. Overheidsdata worden in toenemende mate open source. Big Data. Stef van Grieken is iemand die daar blij van wordt. Met tools als Google BigQuery kunnen databases van honderden terabytes, zoals de Library of Congress in seconden worden doorzocht. Bijeenkomsten als de Amsterdam Hackaton waar ambtenaren en ontwerpers bij elkaar komen laten zien dat het mogelijk is om ogenschijnlijk suffe databronnen binnen een dag te transformeren tot kekke en bruikbare App’s.
De Big Data zijn er. Maar het gaat erom wat je ermee doet. Wat je met wat combineert. Hoe je er zinvolle informatie uithaalt. En hoe snel!
Het roemruchte Apollo project, waarbij single source bereiksonderzoek werd gekoppeld aan gegevens over de boodschappen die mensen in huis haalden is naar mijn mening ten onder gegaan aan het onvermogen om snel genoeg zinvolle informatie uit de enorme hoeveelheid data te genereren. Toen er een jaar na dato allerlei mooie relaties tussen media-inzet en verkoop werden gevonden hadden de deelnemende adverteerders de stekker er al uit getrokken. Stephan Noller van nugg.ad is met behulp van big data in staat om ‘real time’ de juiste online advertentie aan de juiste persoon te laten zien met aanmerkelijke rendementsverbeteringen in termen van verkoopcijfers tot gevolg. 14.000 analyses per seconde bepalen of u een bepaalde advertentie wel of niet te zien krijgt. Overigens gebruikt hij nog steeds traditioneel onderzoek, zowel voor zijn doelgroepselectie als voor het bepalen van de merkeffecten zoals ‘awareness’ en merkvoorkeur.
Mervyn Brookson van Universal Media liet zien dat het mediabureau zich de afgelopen decennia al heeft ontwikkeld tot de partij waar heel veel datastromen bij elkaar komen. Van mediabestedingscijfers, plaatsingsopdrachten, uitzendschema’s, media- en merken tracking, site statistics, tot call center data en verkoopcijfers aan toe. Maar hebben de mediabureaus de kansen die hun positie als dataknooppunt biedt ook voldoende benut?
De grote vraag van de komende jaren zal zijn welke partij of partijen het best in staat zullen zijn om al die groeiende datastromen ‘real time’ te analyseren en te combineren tot zinvolle en bruikbare informatie. Op dit moment claimen alle marktpartijen; onderzoekbureaus, mediabureaus, onlinebureaus, applicatiebouwers, Google, Facebook, partijen als IBM, maar ook de grote consultancy firma’s, dat juist zij bij uitstek geschikt zijn om met Big Data aan de slag te gaan.
Ik kan bij elke partij redenen aangeven waarom zij dat op dit moment zeker nog niet zijn. Stef van Grieken had denk ik wel gelijk toen hij voorstelde dat het geen gek idee zou zijn dat mediabureaus (maar ik denk ook onderzoekbureaus en adverteerders) een ‘pratende nerd’ zouden moeten inhuren die in relatieve vrijheid kan proberen om de ‘Big Data in media’ toekomst vorm te geven.
Recent Comments